From PDFs to Personalized AI: Building a Custom RAG System for IBM Redbooks
In the world of enterprise IT, technical documentation is both invaluable and overwhelming. IBM Redbooks, the gold standard for in-depth technical guides on IBM products, contain thousands of pages of expert knowledge. But how do we transform these static PDFs into dynamic, queryable knowledge bases? Today, I’d like to share a journey of building a custom Retrieval-Augmented Generation (RAG) system specifically for IBM technical documentation. This project demonstrates how modern AI techniques can unlock the knowledge trapped in technical PDFs and make it accessible through natural language queries. The Challenge: Unlocking Technical Knowledge IBM Redbooks are comprehensive technical guides, often hundreds of pages long, covering complex systems like IBM Z mainframes, cybersecurity solutions, and enterprise storage. These documents are treasure troves of information but present several challenges:
- Finding specific information requires sifting through lengthy documents
- Technical complexity makes quick understanding difficult
- Cross-referencing multiple guides is time-consuming
- Format limitations as PDFs aren’t designed for interactive querying
Traditional search approaches fall short with these documents. Keyword searches miss context, and general-purpose AI assistants lack the specific technical knowledge. We needed something better.
The Solution: A Custom RAG Pipeline
My approach combines document understanding technology with local LLMs to create a customized RAG system:
- Advanced document processing using Docling to preserve document structure
- Intelligent chunking that maintains context between sections
- Local AI inference with Ollama and IBM’s Granite models
- Integration with Open WebUI for a user-friendly interface
The magic happens in how these components work together. We’re not just extracting text; we’re preserving the structure, semantics, and technical context of these documents.
Behind the Scenes: The Technical Implementation
Let’s peek under the hood at how this system works:
Document Understanding with Docling
Docling is the unsung hero of this pipeline, providing PDF understanding capabilities beyond basic text extraction:
pythonCopyfrom docling.document_converter import DocumentConverter
from docling.datamodel.pipeline_options import PdfPipelineOptions
# Configure PDF processing options
pipeline_options = PdfPipelineOptions()
# Create document converter
doc_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
}
)
# Process documents
results = doc_converter.convert_all(
input_path_objects,
raises_on_error=False
)
This preserves document structure, understands tables, and even applies OCR to scanned content when needed.
Semantic Chunking for Context Preservation
To maintain the semantic integrity of the content, we implemented a custom chunking algorithm:
# Create chunks using smart boundary detection
chunks = []
start = 0
while start < len(text):
# Extract a chunk
end = min(start + chunk_size, len(text))
# If not at the end, find a good break point
if end < len(text):
# Try to find end of sentence or paragraph
for sep in ["\n\n", "\n", ". ", "! ", "? "]:
pos = text.rfind(sep, start, end)
if pos > chunk_size // 2: # Don't break too early
end = pos + len(sep)
break
This ensures chunks break at natural boundaries like paragraph ends, preserving the coherence of technical explanations.
Local AI with IBM Granite
The system leverages IBM’s Granite models through Ollama for both embedding generation and question answering:
Copy# Build the prompt with context
prompt = f"""You are an IBM Z technical assistant with deep expertise
in IBM mainframe technologies. Your responses are grounded in the
specific IBM Redbooks content provided as context.
{formatted_context}
Question: {query}
Answer:"""
# Send request to Ollama
response = requests.post(
f"{ollama_url}/api/generate",
json={
"model": "granite3.2:8b-instruct-fp16",
"prompt": prompt,
"temperature": 0.7,
"max_tokens": 500,
"stream": False
}
)
The carefully engineered prompt ensures the model stays grounded in the retrieved documentation.
The Results: Technical Knowledge at Your Fingertips
The finished system transforms how we interact with technical documentation. Instead of keyword searches and manual reading, we can now ask natural language questions:
- “What are the cryptographic finctions for CPACF?”
- “What are the recovery options for an IBM Z system?”
- “Explain the architecture of IBM Z Cyber Vault’s air-gapped protection.”
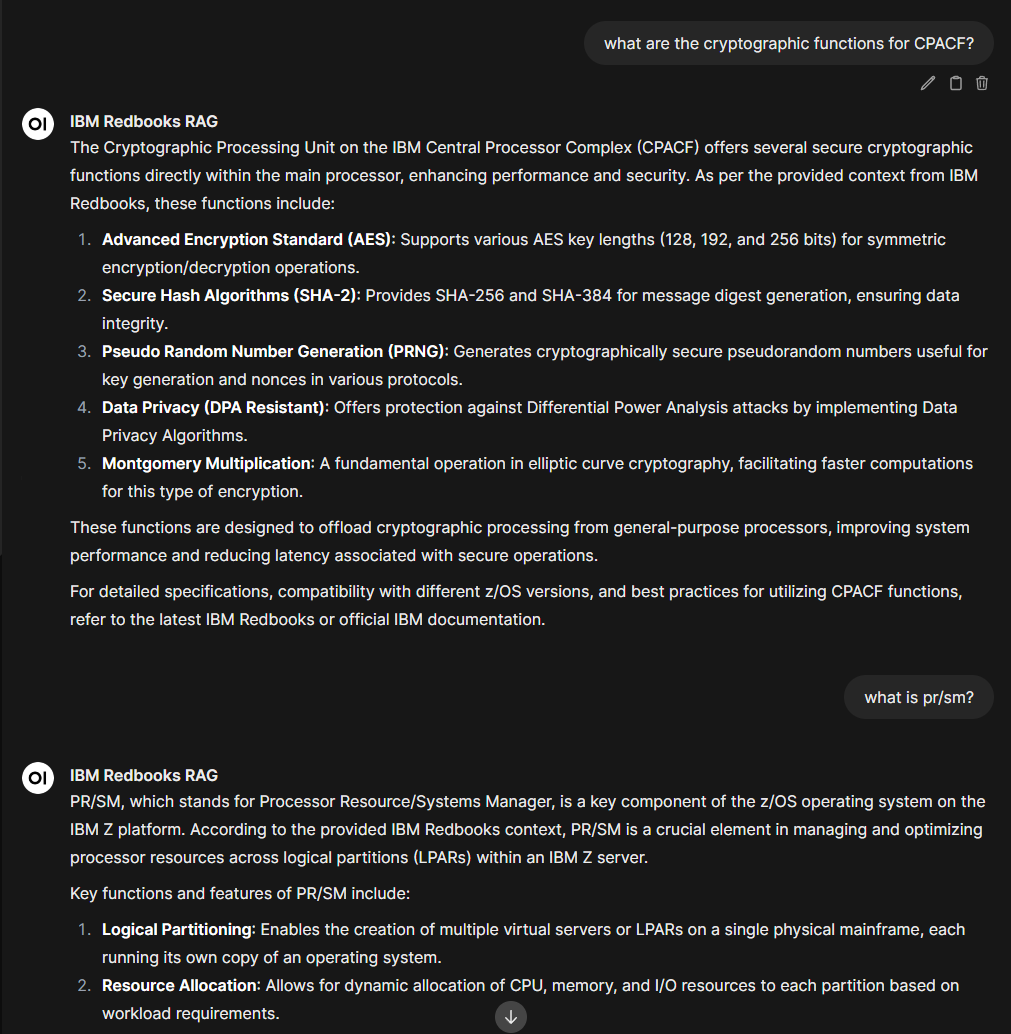
The responses are concise, accurate, and specifically drawn from the IBM Redbooks I’ve processed. When information isn’t in the documentation, the system honestly acknowledges this rather than hallucinating.
Beyond Proof of Concept: Real-World Applications
This project demonstrates far more than a technical curiosity. It shows a practical approach to:
- Technical support augmentation - helping support teams quickly access documentation
- Self-service knowledge bases - enabling users to find answers without waiting for support
- Technical training acceleration - allowing new team members to quickly learn complex systems
- Documentation improvement - identifying gaps in existing documentation
Looking Forward: Expanding the System
While this implementation focuses on IBM Redbooks, the approach can be extended to any technical documentation. Future enhancements could include:
- Multi-modal understanding of diagrams and technical illustrations
- Cross-document reasoning to connect information across multiple sources
- Temporal awareness to account for version differences in documentation
- User feedback incorporation to improve retrieval accuracy over time
Conclusion: The Future of Technical Documentation
This project represents a fundamental shift in how we interact with technical documentation. Static PDFs become dynamic knowledge sources; complex technical concepts become accessible through conversation. As we continue to refine this approach, the boundary between documentation and interactive assistance will blur. The future isn’t just about having access to information—it’s about having that information respond to you. What technical documentation would you like to make more accessible through AI? The possibilities are as endless as they are exciting.